| ||
| State transitions | ||
|---|---|---|
| Prev | State transition diagram | Next |
This section describes state transitions for:
Opening a resource
Resource in a steady state
Bringing a resource online
Taking a resource offline
Resource fault (without automatic restart)
Resource fault (with automatic restart)
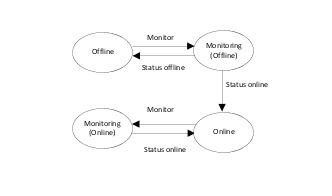
Monitoring of persistent resources
Closing a resource
Migrating a resource
In addition, state transitions are shown for the handling of resources with respect to the ManageFaults service group attribute.
See State transitions with respect to ManageFaults attribute.
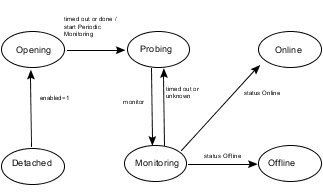
The states shown in these diagrams are associated with each resource by the agent framework. These states are used only within the agent framework and are independent of the IState resource attribute values indicated by the engine.
The agent writes resource state transition information into the agent log file when the LogDbg parameter, a static resource type attribute, is set to the value DBG_AGINFO. Agent developers can make use of this information when debugging agents.
When the agent starts up, each resource starts with the initial state of Detached. In the Detached state (Enabled=0), the agent rejects all commands to bring a resource online or take it offline.
When resources are in a steady state of Online or Offline, they are monitored at regular intervals. The intervals are specified by the MonitorInterval attribute in the Online state and by the OfflineMonitorInterval attribute in the Offline state. An Online resource that is unexpectedly detected as Offline is considered to be faulted. Refer to diagrams describing faulted resources.
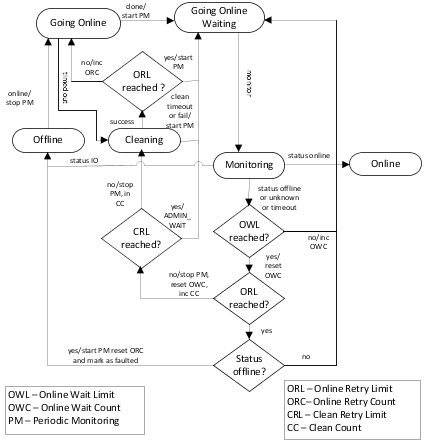
When the agent receives a request from the engine to bring the resource online, the resource enters the Going Online state, where the online entry point is invoked.
If online entry point completes, the resource enters the Going Online Waiting state where it waits for the next monitor cycle.
If online entry point timesout, the agent call clean.
If monitor of GoingOnlineWaiting state returns a status as online, the resource moves to the Online state.
If monitor of GoingOnlineWaiting state returns a status as Intentional Offline, the resource moves to the Offline state.
If, however, the monitor times out, or returns a status of "not Online" (that is, unknown or offline), the following actions are considered:
If OnlineWaitLimit is not reached then resource returns to GoingOnlineWaiting and waits for next monitor.
If OnlineWaitLimit and OnlineRetryLimit are reached and the status remains unknow then resource returns to GoingOnlineWaiting and waits for next monitor.
If OnlineWaitLimit and OnlineRetryLimit are reached then the status remains offline then resource return to Offline state and marks the resource as faulted.
If OnlineWaitLimit is reached and OnlineRetryLimit is not reached then run clean, if CleanRetryLimit is not reached.
If OnlineWaitLimit and CleanRetryLimit are reached and OnlineRetryLimit is not reached then move the resource to GoingOnlineWaiting and mark it as ADMIN_WAIT.
If CleanRetryLimit is not reached and agent calls clean then following things can happen:
If clean times out or fails, the resource again returns to the Going Online Waiting state and waits for the next monitor cycle.
If clean succeeds with the OnlineRetryLimit reached, and the subsequent monitor reports the status as offline, the resource transitions to the offline state and it is marked as FAULTED.
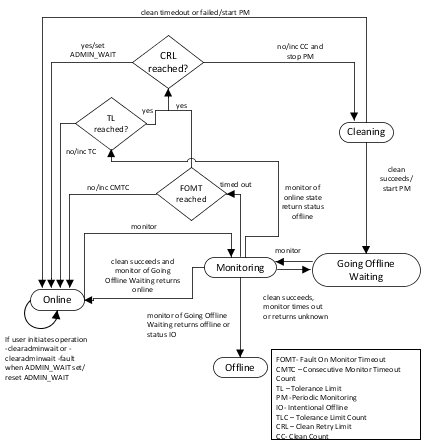
Upon receiving a request from the engine to take a resource offline, the agent places the resource in a GoingOffline state and invokes the offline entry point and stop periodic monitoring.
If offline completes, the resource enters the GoingOffline Waiting state, agent starts periodic monitoring of resource and also insert a monitor command for the resource. If offline times out, the clean entry point is called for the resource. If clean times out or complete then start periodic monitoring and reset Offline Wait Count if clean was success and move resource to Going Offline Waiting state
If monitor of Going Offline Waiting state returns offline or intentional offline then resource moves to offline state
If monitor of the GoingOffline Waiting state returns unknown or online, or if the monitor times out then,
If OfflineWait Limit is not reached then the resource is moved to GoingOffline Waiting state.
If Offline Wait Limit is reached then the resource which is cleaned earlier is called, then mark the resource as UNABLE_TO_OFFLINE
If CleantRetryLimit is not reached then call clean.
If CleantRetryLimit is reached then mark resource as ADMIN_WAIT state and move the resource to GoingOffline Waiting state.
If the user initiates operation "-clearadminwait" then reset the ADMIN_WAIT flag. If user initiates operation "-clearaminwait -fault" then agent resets the ADMIN_WAIT flag
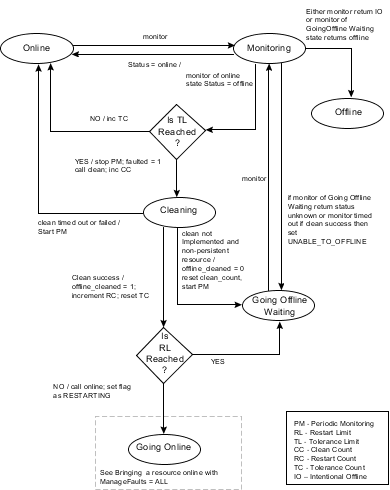
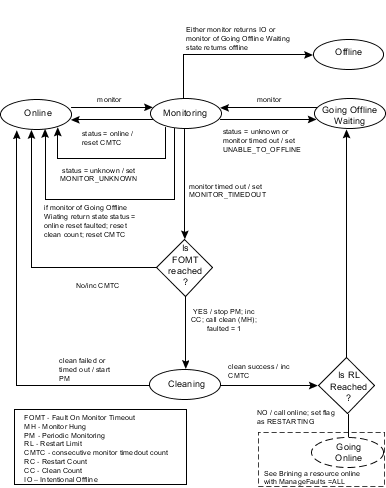
This diagram describes the activity that occurs when a resource faults and the RestartLimit is reached. When the monitor entry point times out successively and FaultOnMonitorTimeout is reached, or monitor returns offline and the ToleranceLimit is reached.
If clean retry limit is reached then set ADMIN_WAIT flag for resource and move resource to online state if not reached the agent invokes the clean entry point.
If clean fails, or if it times out, the agent places the resource in the online state as if no fault has occurred and starts periodic monitoring. If clean succeeds, the resource is placed in the Going Offline Waiting state and start periodic monitoring, where the agent waits for the next monitor.
If clean succeeds, the resource is placed in the GoingOffline Waiting state, where the agent waits for the next monitor.
If monitor reports online, the resource is placed back online as if no fault occurred. If monitor reports offline, the resource is placed in an offline state and marked as FAULTED. If monitor reports IO, the resource is placed in an offline state
If monitor reports unknown or times out, the agent places the resource back into the Going Offline Waiting state, and sets the UNABLE_TO_OFFLINE flag.
This diagram describes the activity that occurs when a resource faults and the RestartLimit is not reached. When the monitor entry point times out successively and FaultOnMonitorTimeout is reached, or monitor returns offline and the ToleranceLimit is reached then agent checks the clean counter to check if the clean entry point can be invoked.
If CleanRetryLimit is reached then set ADMIN_WAIT flag for the resource and move the resource to online state. If clean retry limit fails to reach, the agent invokes the clean entry point.
If clean succeeds, the resource is placed in the Going Online state and the online entry point is invoked to restart the resource; refer to the diagram, "Bringing a resource online."
If clean fails or times out, the agent places the resource in the Online state as if no fault occurred.
Refer to the diagram "Resource fault without automatic restart," for a discussion of activity when a resource faults and the RestartLimit is reached.
If monitor returns offline and the ToleranceLimit is reached, the resource is placed in an Offline state and noted as FAULTED. If monitor timeout and FaultOnMonitorTimeouts is reached, the resource is placed in an Offline state and noted as FAULTED.
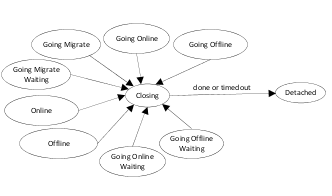
The state diagram explains all the states from where a resource can move to Closing state. The following tables describes the actions performed in different state by which a resource can move to Closing state,
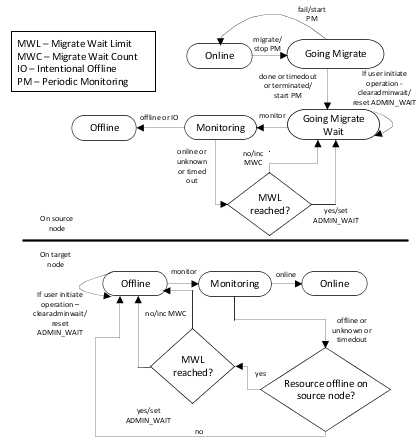
The migration process is initiated from the source system, where virtual machine (VM) is online and the VM is migrated to the target system where it was offline. When the agent on the source system receives a migration request from the engine to migrate the resource, the resource goes to Going Migrate state, where migrate entry point is invoked. If the migrate entry point fails with return code 255, the resource is transitioned back to the online state and failure of migrate operation is communicated to the engine. This indicates that the migration operation cannot be performed.
Agent framework ignores any value returned between 101 to 254 range and will return to online state. If the migrate entry point completes successfully or times out is reached, the resource enters the Going Migrate Waiting state where it waits for the next monitor cycle and the monitor calls with the frequency as configured in MonitorInterval. If monitor returns an offline status, the resource moves to the offline state and the migration on the source system is considered complete.
Even after moving to offline state the agent keeps on monitoring the resource with same monitor frequency as configured in MonitorInterval. This is to detect if VM fails back at source node early. However, if monitor entry point times out or reports the state as online or unknown, the resource waits for the MigrateWaitLimit resource cycle to complete.
If any of the monitor within MigrateWaitLimit reports the state as offline, the resource transitions to offline state and the same is reported to the engine. If the monitor entry point times out or reports the state as online or unknown even after MigrateWaitLimit has reached, the ADMIN_WAIT flag is set.
If resource migration operation is successful on source node then on target node the agent change the monitoring frequency from OfflineMonitorInterval to MonitorInternal to detect success full migration early. But if resource is not detected as online on target node even after MigrateWaitLimit is reached then resource is moved to ADMIN_WAIT state and agent fail back to monitor frequency as configured in OfflineMonitorInterval