| ||
| Example: Four-system cluster where cluster interconnect fails | ||
|---|---|---|
| Prev | Examples of VCS operation with I/O fencing | Next |
| ||
| Example: Four-system cluster where cluster interconnect fails | ||
|---|---|---|
| Prev | Examples of VCS operation with I/O fencing | Next |
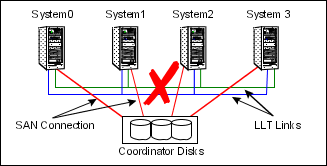
In this example, the cluster interconnect fails in such a way as to split the cluster from one four-system cluster to two-system clusters. The cluster performs membership arbitration to ensure that only one subcluster remains.
Due to loss of heartbeat, System0 and System1 both believe System2 and System3 are down. System2 and System3 both believe System0 and System1 are down.
The progression of I/O fencing operations are as follows:
LLT on each of the four systems no longer receives heartbeat messages from the systems on the other side of the interconnect failure on any of the configured LLT interfaces for the peer inactive timeout configured time.
LLT on each system passes to GAB that it has noticed a membership change. Specifically:
After LLT informs GAB of a heartbeat loss, the systems that are remaining do a "GAB Stable Timeout" (5 seconds). In this example:
GAB marks the system as DOWN, and excludes the system from the cluster membership. In this example:
GAB on each of the four systems passes the membership change to the vxfen driver for membership arbitration. Each subcluster races for control of the coordinator disks. In this example:
GAB on each of the four systems also passes the membership change to HAD. HAD waits for the result of the membership arbitration from the fencing module before taking any further action.
If System0 is not able to reach a majority of the coordination points, then the VxFEN driver will initiate a racer re-election from System0 to System1 and System1 will initiate the race for the coordination points.
Assume System0 wins the race for the coordinator disks, and ejects the registration keys of System2 and System3 off the disks. The result is as follows:
System0 wins the race for the coordinator disk. The fencing module on System0 sends a WON_RACE to all other fencing modules in the current cluster, in this case System0 and System1. On receiving a WON_RACE, the fencing module on each system in turn communicates success to HAD. System0 and System1 remain valid and current members of the cluster.
If System0 dies before it sends a WON_RACE to System1, then VxFEN will initiate a racer re-election from System0 to System1 and System1 will initiate the race for the coordination points.
System1 on winning a majority of the coordination points remains valid and current member of the cluster and the fencing module on System1 in turn communicates success to HAD.
System2 loses the race for control of the coordinator disks and the fencing module on System 2 sends a LOST_RACE message. The fencing module on System2 calls a kernel panic and the system restarts.
System3 sees another membership change from the kernel panic of System2. Because that was the system that was racing for control of the coordinator disks in this subcluster, System3 also panics.
HAD carries out any associated policy or recovery actions based on the membership change.
System2 and System3 are blocked access to the shared storage (if the shared storage was part of a service group that is now taken over by System0 or System 1).
To rejoin System2 and System3 to the cluster, the administrator must do the following: