| ||
| About disaster recovery clusters | ||
|---|---|---|
| Prev | Introducing SFW solutions for a Microsoft cluster | Next |
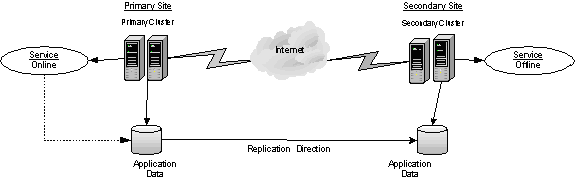
A typical disaster recovery configuration requires that you have a source host on the Primary site and a destination host on the Secondary site. The application data is stored on the Primary site and replicated to the Secondary site by using a tool such as the Volume Replicator. The Primary site provides data and services during normal operation. If a disaster occurs on the Primary site and its data is destroyed, a Secondary host can take over the role of the Primary host to make the data accessible. The application can be restarted on that host.
Using Volume Replicator with Microsoft clustering provides a replicated backup of your application data, which can be used for recovery after an outage or disaster. However, this solution does not provide the automated failover capability for disaster recovery that can be achieved using Volume Replicator with Cluster Server (VCS).
In a typical clustered Volume Replicator configuration the Primary site consists of two nodes, SYSTEM1 and SYSTEM2. Similarly the Secondary setup consists of two nodes, SYSTEM3 and SYSTEM4. Each site has a clustered setup with the nodes set up appropriately for failover within the site. In a Microsoft cluster environment, each site has its own quorum volume.
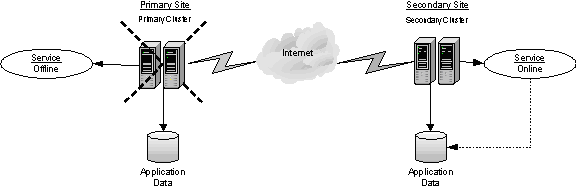
If the SYSTEM1 fails, the application comes online on node SYSTEM2 and begins servicing requests. From the user's perspective there might be a small delay as the backup node comes online, but the interruption in effective service is minimal. When a failure occurs (for instance, after an earthquake that destroys the data center in which the Primary site resides), the replication solution is activated. If there is a disaster at the Primary site, SYSTEM3 at the Secondary site takes over. The data that was replicated to the Secondary site is used to restore the application services to clients.
The following figure shows an example disaster recovery configuration before a failure.
The following figure shows an example disaster recovery configuration after a failure.