| ||
| Illustrating a highly available Volume Replicator setup | ||
|---|---|---|
| Prev | Configuring Volume Replicator in a VCS environment | Next |
| ||
| Illustrating a highly available Volume Replicator setup | ||
|---|---|---|
| Prev | Configuring Volume Replicator in a VCS environment | Next |
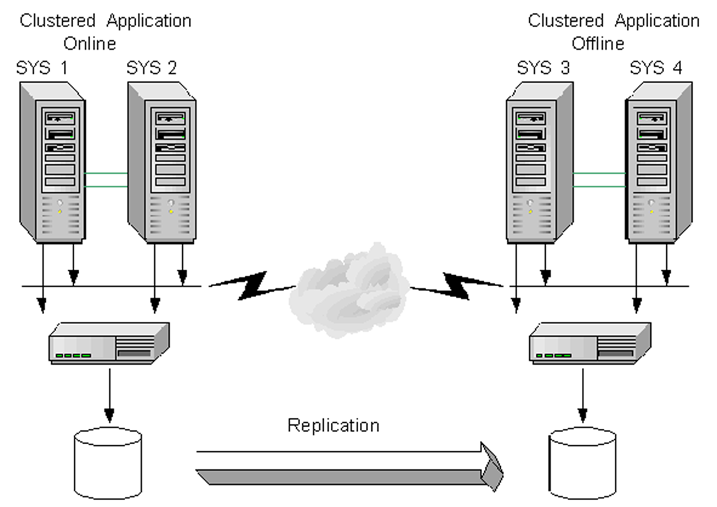
The illustration below shows a configuration where application data is replicated from a Primary site to the Secondary site. This provides disaster recovery; in the event that the Primary site is destroyed, application data is immediately available at the Secondary site, and the application can be restarted at the Secondary site.
On each site, a VCS cluster provides high availability to both the application and the replication. A VCS cluster is configured at the Primary site, and another cluster at the Secondary site. If a single clustered node fails at either site, any online group of resources can failover to other nodes in the VCS cluster. The VvrRvg agent is installed and configured on each VCS node to enable the Volume Replicator RVGs to failover between nodes in a VCS cluster. Note that while a replication group is online on both sites to handle both sides of the replication (source and destination), the clustered application is online only on the Primary site. The application data on the Secondary site is accessible after a takeover or migrate operation.
The RVGPrimary agent can be configured on all the nodes. This agent can also be used to automate the process of takeover in case of a failure of the Primary cluster. In a setup with multiple Secondary hosts where the RLINKs between the Secondaries are already created, this agent also automates the process of adding the orphan Secondaries back into the RDS after failover and also synchronizes these Secondaries with the new Primary.