This section presents an example of how a serial split brain condition might occur for a shared disk group in a cluster. Conflicts between configuration copies can also occur for private disk groups in clustered and non-clustered configurations where the disk groups have been partially imported on different systems.
A campus cluster (also known as a stretch cluster or remote mirror configuration) typically consists of a 2-node cluster where each component (server, switch and storage) of the cluster exists in a separate building.
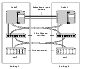
Typical arrangement of a 2-node campus cluster shows a 2-node cluster with node 0, a fibre channel switch and disk enclosure enc0 in building A, and node 1, another switch and enclosure enc1 in building B.
Typical arrangement of a 2-node campus cluster
Click the thumbnail above to view full-sized image.
The fibre channel connectivity is multiply redundant to implement redundant-loop access between each node and each enclosure. As usual, the two nodes are also linked by a redundant private network.
A serial split brain condition typically arises in a cluster when a private (non-shared) disk group is imported on Node 0 with Node 1 configured as the failover node.
If the network connections between the nodes are severed, both nodes think that the other node has died. (This is the usual cause of the split brain condition in clusters). If a disk group is spread across both enclosure enc0 and enc1, each portion loses connectivity to the other portion of the disk group. Node 0 continues to update to the disks in the portion of the disk group that it can access. Node 1, operating as the failover node, imports the other portion of the disk group (with the -f option set), and starts updating the disks that it can see.
When the network links are restored, attempting to reattach the missing disks to the disk group on Node 0, or to re-import the entire disk group on either node, fails. This serial split brain condition arises because VxVM increments the serial ID in the disk media record of each imported disk in all the disk group configuration databases on those disks, and also in the private region of each imported disk. The value that is stored in the configuration database represents the serial ID that the disk group expects a disk to have. The serial ID that is stored in a disk's private region is considered to be its actual value.
If some disks went missing from the disk group (due to physical disconnection or power failure) and those disks were imported by another host, the serial IDs for the disks in their copies of the configuration database, and also in each disk's private region, are updated separately on that host. When the disks are subsequently re-imported into the original shared disk group, the actual serial IDs on the disks do not agree with the expected values from the configuration copies on other disks in the disk group.
Depending on what happened to the different portions of the split disk group, there are two possibilities for resolving inconsistencies between the configuration databases:
update_tid in the output from the vxdg list diskgroup command).
Example of a serial split brain condition that can be resolved automatically shows an of a serial split brain condition that can be resolved automatically by VxVM.
Example of a serial split brain condition that can be resolved automatically

Click the thumbnail above to view full-sized image.
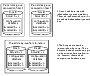
Example of a true serial split brain condition that cannot be resolved automatically shows an example of a true serial split brain condition that cannot be resolved automatically by VxVM.
Example of a true serial split brain condition that cannot be resolved automatically
Click the thumbnail above to view full-sized image.
In this case, the disk group import fails, and the vxdg utility outputs error messages similar to the following before exiting:
VxVM vxconfigd NOTICE V-5-0-33 Split Brain. da id is 0.1, while dm id is 0.0 for DM mydg01
VxVM vxdg ERROR V-5-1-587 Disk group newdg: import failed: Serial Split Brain detected. Run vxsplitlines
The import does not succeed even if you specify the -f flag to vxdg.
Although it is usually possible to resolve this conflict by choosing the version of the configuration database with the highest valued configuration ID (shown as config_tid in the output from the vxdg list diskgroup command), this may not be the correct thing to do in all circumstances.
See "Correcting conflicting configuration information" on page 203.
See "Administering sites and remote mirrors" on page 435.