| ||
| How VCS replicated data clusters work | ||
|---|---|---|
| Prev | Setting up replicated data clusters | Next |
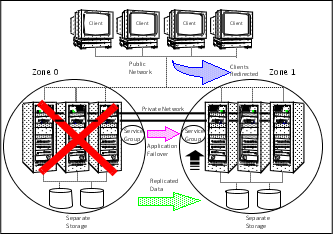
To understand how a replicated data cluster configuration works, let us take the example of an application configured in a VCS replicated data cluster. The configuration has two system zones:
Primary zone (zone 0) comprising nodes located at the primary site and attached to the primary storage
Secondary zone (zone 1) comprising nodes located at the secondary site and attached to the secondary storage
The application is installed and configured on all nodes in the cluster. Application data is located on shared disks within each RDC zone and is replicated across RDC zones to ensure data concurrency. The application service group is online on a system in the current primary zone and is configured to fail over in the cluster.
Figure: A VCS replicated data cluster configuration depicts an application configured on a VCS replicated data cluster.
In the event of a system or application failure, VCS attempts to fail over the application service group to another system within the same RDC zone. However, in the event that VCS fails to find a failover target node within the primary RDC zone, VCS switches the service group to a node in the current secondary RDC zone (zone 1). VCS also redirects clients once the application is online on the new location.